-
logback配置忽略日志
一直用`log4j`,最近使用百度的云存储,用到了`logback`,但是有个`info`日志实在是让人受不了:```17:36:38.118[http-nio-8080-exec-83]INFOcom.baidubce.http.BceHttpClient-UnabletoexecuteHTTPrequestcom.baidubce.BceServiceException:Thespecifiedkeydoesnotexist.(StatusCode:404;ErrorCode:NoSuchKey;RequestID:48c1e2c3-b159-4085-b0bc-033bcdb27de3)atcom.baidubce.http.handler.BceErrorResponseHandler.handle(BceErrorResponseHandler.java:51)~[bce-java-sdk-0.9.1.jar:na]```就是删除不存在的`object`的时候,日志里面一堆的错误信息。怎么过滤这个日志呢?我开始想的是能不能过滤掉这个异常`com.baidubce.BceServiceExceptio...
logback 日志 -
PHP错误
错误信息:```PHPWarning:PHPStartup:ftp:UnabletoinitializemoduleModulecompiledwithmoduleAPI=20131226PHPcompiledwithmoduleAPI=20090626TheseoptionsneedtomatchinUnknownonline0```这个是因为`phpize`的版本和当前的`php`版本不一致,我们最好直接使用`phpize`,而不是加上路径。
PHP phpize -
Eclipse优化以及配置
如果找不到可以直接搜索关键词(括号内的单词)。##关闭拼写检查(spelling)>Window->Preferences->General->Editors->TextEditors->Spelling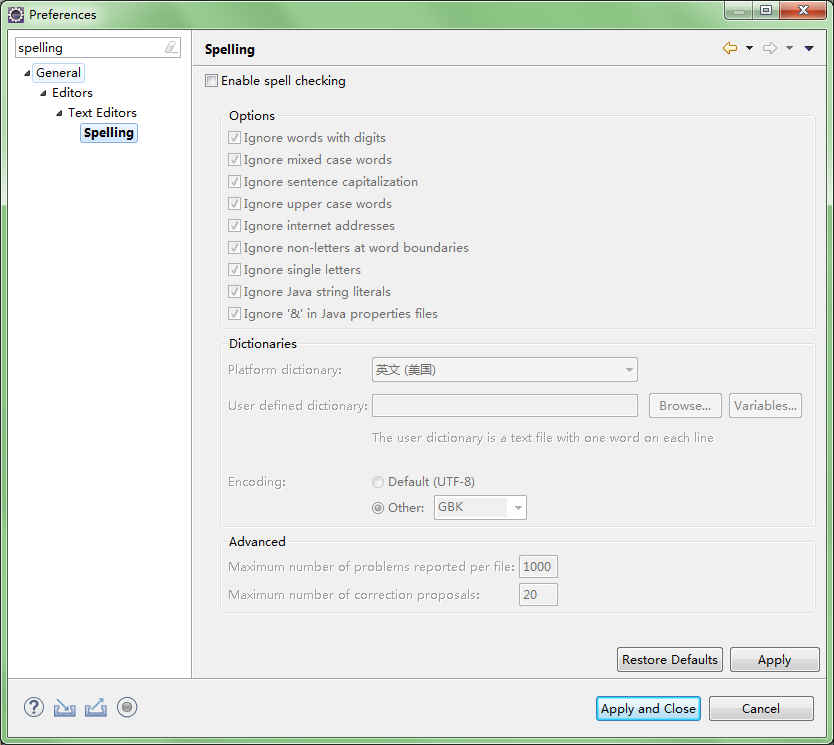##编码优化(encoding)>修改配置较多,使用搜索比较方便。##显示内存使用(heap)>Window->Preferences->General->Showheapstatus##关闭校验(validation)>修改配置较多,使用搜索比较方便。##字体优化(font)>Window->Preferences->General->Appearance->ColorsandFonts->Basic(改为中欧字符)##关闭动画>Window->Preferences->General->Appeara...
Eclipse -
Eclipse配置Tomcat
我们使用Eclipse配置Tomcat的时候,总是修改文件后,Tomcat就自动重启了。其实Eclipse经常出现这个问题,最近我自己配置了一下,暂时没发现什么问题:首先修改配置文件的内存: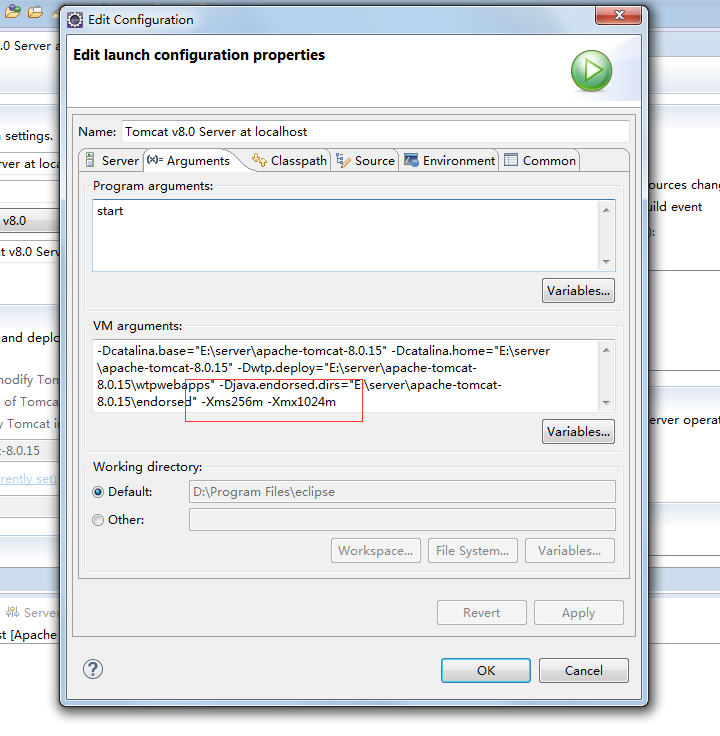然后修改`server.xml`,去掉`autoDeploy`和`reloadable`:
Eclipse Tomcat PermGen space -
browserconfig.xml
最近看服务器访问日志,看到好多`404`都是请求的`browserconfig.xml`文件,最后百度了一下,原来是IE最新的浏览器的一些功能。是配置Window8.1以上系统的开始菜单的,好像还可以配置一些通知信息,挺不错的东西,可惜是IE上面的东西。>具体配置参考:[https://msdn.microsoft.com/library/dn455106(v=vs.85).aspx](https://msdn.microsoft.com/library/dn455106(v=vs.85).aspx)
browserconfig.xml -
Linux find regex
Linux的`find`命令真是非常强大的命令。以前都是用通配符的,但是最近有些东西通配符已经不能解决了,所以用到了正则表达式,但是发现每次使用的时候都找不到文件:```bashfind./-regex'acgist\.log.*'```这是为什么了,机智的我总能发现问题,我们使用`find`命令的时候会发现找到的文件名都是**./文件名**的格式的,所以应该这样写:```bashfind./-regex'\.\/acgist\.log.*'```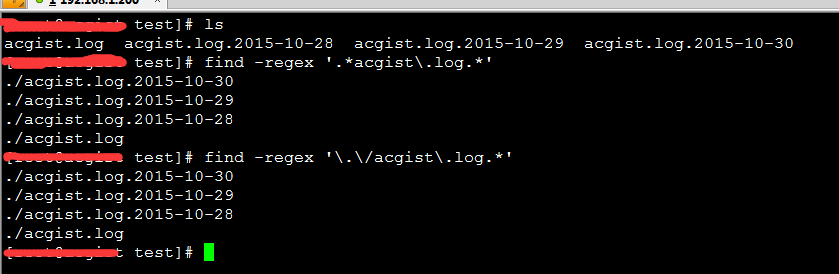当然上面还有一种`.*acgist\.log.*`的也可以。
Linux find regex 正则表达式 -
MySQL INTO OUTFILE和LOAD DATA INFILE
有时候为了方便拿到数据,会使用一些工具来转移数据,但是这样非常慢,使用MySQL自带的工具效率会高很多。下面就给一个文件来转移数据的例子,当然数据很多可以使用`mysqldump`命令更快。```sqlselectid,name,infofromxx_memberwherecreate_date>'2015-10-01'INTOOUTFILE"/data.txt"FIELDSTERMINATEDBY','LINESTERMINATEDBY'\n';```然后load到数据库:```sqlLOADDATAINFILE'E://company/data.txt'INTOTABLExx_memberFIELDSTERMINATEDBY','LINESTERMINATEDBY'\n'(id,name,info);```>这里要注意的就是后面`load`到数据库的时候,列的位置不是跟在表后面,而是放在最后面的。
INTO OUTFILE LOAD DATA INFILE MySQL -
xargs带有空格名称解决办法
我们一般使用`find`和`xargs`两个命令完成一些功能,但是今天发现如果包含有空格的文件却会提示:```未匹配的单引用;默认情况下,引用是针对xargs的,除非您使用了-0选项```直接上解决办法:原命令:```bashfind/home/test/-name"*.text"-mtime+2|xargsls-lh```修改为:```bashfind/home/test/-name"*.text"-mtime+2-print0|xargs-0ls-lh```>参考文章:[http://blog.chinaunix.net/uid-7242899-id-2060739.html](http://blog.chinaunix.net/uid-7242899-id-2060739.html)
xargs -
UEditor表格无边框
最近改用UEditor,一连串悲催的故事就发生了。今天就遇到了表格无边框的问题。当然百度有很多解决办法,但是我用的这个版本好像都没用,因为这个SB玩意把边框样式写到了CSS里面。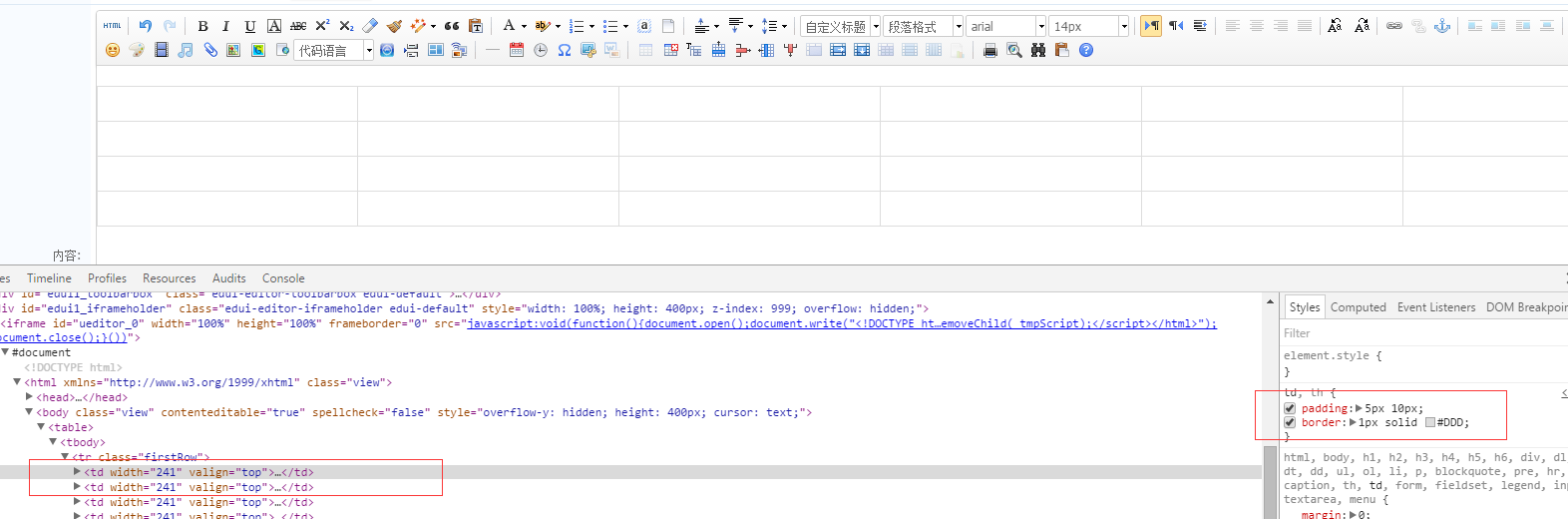解决办法两个:1.直接把样式写到前台CSS里面2.改JS咯,搜索`c.push('20220623批注现在改成了Markdown写文章了,感觉富文本编辑器里面的标签比较乱,Markdown生成HTML比较好控制。
UEditor -
Grunt编译UEditor
最近把公司网站的编辑器换了一下,原来的有点渣,换用百度的`UEditor`,但是发现百度官网的下载包有BUG(预览图片的时候路径是本地路径)。我还在想这么严重的问题百度居然不修复,原来百度早已经把源代码放到了`github`上面去了。下载源代码发现根本不是那么回事情,不得不说现在的前端也是折腾的厉害啊,什么自动化测试、编译,还要学习([http://www.gruntjs.net/](http://www.gruntjs.net/))。*首先从github上面下载代码下来*然后安装node.js*然后安装grunt插件*最后编译就OK了具体命令:```javascriptnode--versionnpminstall-ggrunt-clinpminstallgrunt--save-devnpminstallgrunt```>参考文章:[http://www.cnblogs.com/linjiqin/p/3754771.html](http://www.cnblogs.com/linjiqin/p/3754771.html)结果如下图:##选中Workspace##选择你的Workspace目录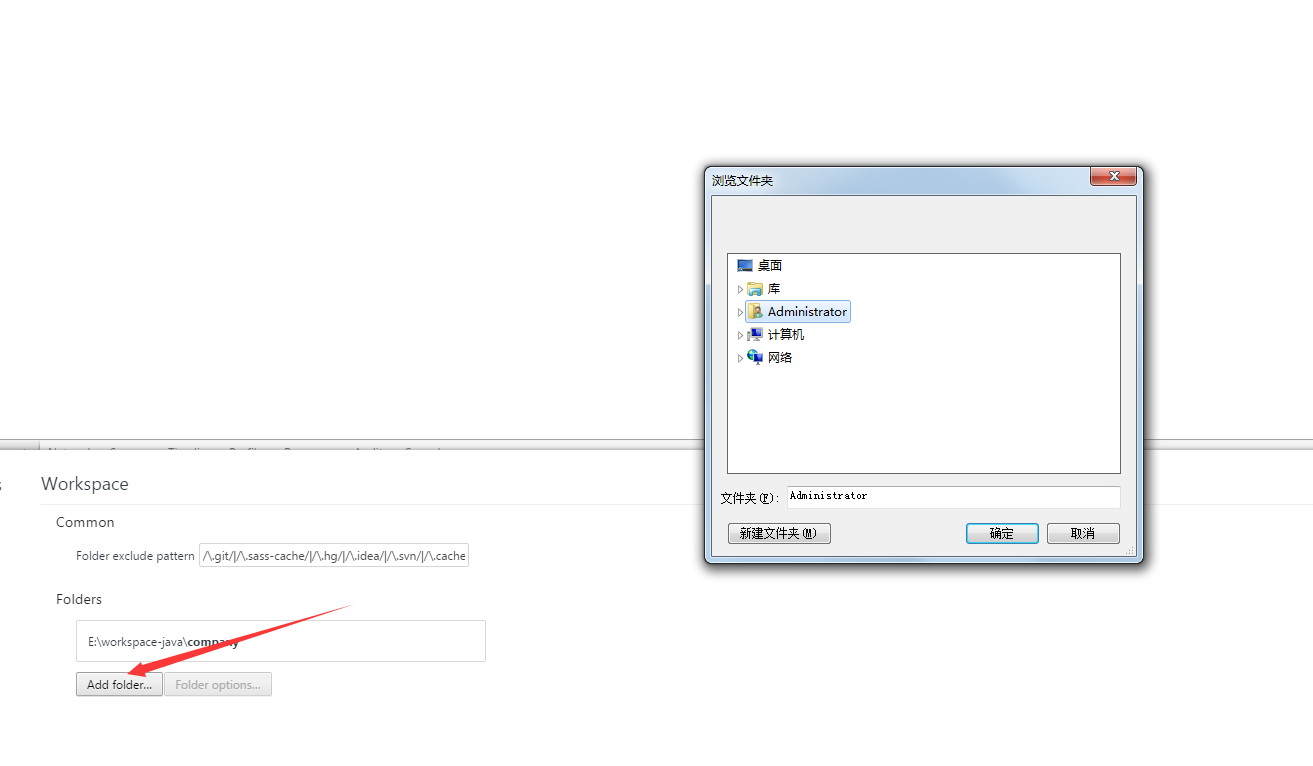##设置folder的属性设置映射文件,可以映射本地文件,也可以映射`http://xxxx`文件,但是目录的层级要一样。![映射文件]...
Chrome Workspace -
中文分词
下面是一个中文分词算法,只有片段,完整例子请在后面下载完整代码:```javapackagecom.acgist.nlp.query.analyzer;importjava.util.ArrayList;importjava.util.List;importorg.apache.commons.lang.StringUtils;/***分词器*注意词典必须有序排放*/publicclassAnalyzer{privatechar[]chars;//字符串分割privateintindex=0;//分词序号privateintmatchIndex=0;//已经匹配的长度privateStringcontent;//原始句子privatebooleanmaximize;//是否最大分词privateListtokens;//分解出来的词语publicstaticfinalStringREGEX_BLANK="\\s";publicstaticfinalStringREGEX_NUMBER="[0-9]";publicstaticfinalStringREGEX_LETTER="[a-zA-Z]";publicst...
中文分词 -
StringBuffer小细节
以前每次说到使用`StringBuffer`来拼接字符串,但是当使用`toString`的方法时要小心。例如下面的代码:```javapublicstaticvoidmain(String[]args){StringBufferbuffer=newStringBuffer();longbegin=System.currentTimeMillis();for(inti=0;i<1000*10000;i++){if(buffer.toString().equals("bb")){}}longend=System.currentTimeMillis();System.out.println(end-begin);begin=System.currentTimeMillis();Stringvalue=buffer.toString();for(inti=0;i<1000*10000;i++){if(value.equals("bb")){}}end=System.currentTimeMillis();System.out.println(end-begin);}```如果每次比较的时候都去调用`toS...
StringBuffer -
Spring MVC匹配多个value
最近搞SEO得优化,以前的一些链接优化,本来想用Nginx重写,但是想了想还是新站,还是改代码算了。需求是同时匹配:`icon|graph|ppt|image|font|soft`本来想的是:`@RequestMapping(value={"icon","graph","ppt","image","font","soft"})`,但是这样取不到值,还要自己写取值的方法。最后百度一下,原来还可以使用正则表达式:```java@RequestMapping(value="/{type:icon|graph|ppt|image|font|soft}")```>参考文章:[http://my.oschina.net/guhai2004/blog/170133](http://my.oschina.net/guhai2004/blog/170133)
Spring MVC @RequestMapping @PathVariable -
lucene多个field查询
一般使用`lucene`查询可能都是下面这样:```javakeyword=QueryParser.escape(keyword);QueryParserqueryParser=newQueryParser(field,newAnalyzer());IndexSearchersearch=newIndexSearcher(indexReader);TopDocstopDocs=search.search(queryParser.parse(keyword),size);if(topDocs!=null){for(inti=0;i<topDocs.scoreDocs.length;i++){docs.add(search.doc(topDocs.scoreDocs[i].doc));}}```如果多列查询怎么办?如下:```javaintlength=fields.length;BooleanClause.Occur[]occurs=newBooleanClause.Occur[length];//对应列关键词的情况for(inti=0;i<length;i++){occurs[i]=Boolean...
lucene MultiFieldQueryParser -
lucene转义
```org.apache.lucene.queryparser.classic.ParseException:Cannotparse'?':'*'or'?'notallowedasfirstcharacterinWildcardQueryatorg.apache.lucene.queryparser.classic.QueryParserBase.parse(QueryParserBase.java:125)atorg.apache.lucene.queryparser.classic.MultiFieldQueryParser.parse(MultiFieldQueryParser.java:307)atcom.acgist.module.search.utils.IndexReaderUtils.searchIndex(IndexReaderUtils.java:66)atcom.acgist.module.search.utils.SearchUtils.search(SearchUtils.java:16)atcom.acgist.controller.SearchController.index(...
lucene -
lucene自定义分词器
小黄书的分词很久就写好了,但是怎么结合`lucene`呢?首先要实现一个`Analyzer`的抽象类:```javapublicclassNLPAnalyzerextendsAnalyzer{@OverrideprotectedTokenStreamComponentscreateComponents(Stringfield){returnnewTokenStreamComponents(newNLPTokenizer());}}```代码非常简单,主要就是`NLPTokenizer`这个东西非常重要的,里面就是实现分词的代码:```javapublicclassNLPTokenizerextendsTokenizer{@OverridepublicbooleanincrementToken()throwsIOException{//内置input获取文本内容“你喜欢吃苹果吗?”clearAttributes();//清空CharTermAttributeterm=addAttribute(CharTermAttribute.class);term.append("分词");returntrue;}}```&...
lucene 分词器 -
手机浏览器拉起微信和支付宝
手机其他浏览器支付时如何拉起微信和支付宝呢?微信:[weixin://wxpay/bizpayurl?pr=3yrtD05](weixin://wxpay/bizpayurl?pr=3yrtD05)其实部分`APP`有自己的`schame`,例如支付宝是`alipays://`。包括PC微信也可以通过`weixin://`打开。
微信 支付宝 -
Java版MongoDB驱动Bson小技巧
我这里使用的驱动是`3.0.1`,API地址:[http://mongodb.github.io/mongo-java-driver/](http://mongodb.github.io/mongo-java-driver/)Bson主要就是做一些`CURD`的条件,如下图: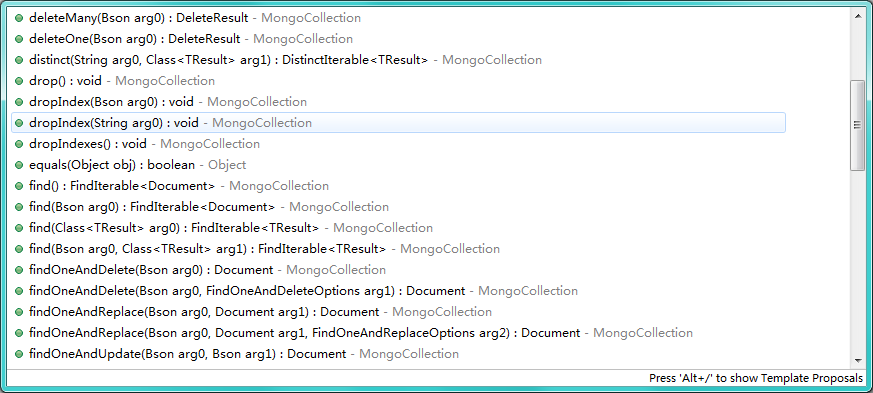其实非常简单的,主要使用到的一个工具类`Filters`,一看名字就是知道是一个过滤的工具。里面的方法都是静态的,而且都是查询条件使用到的: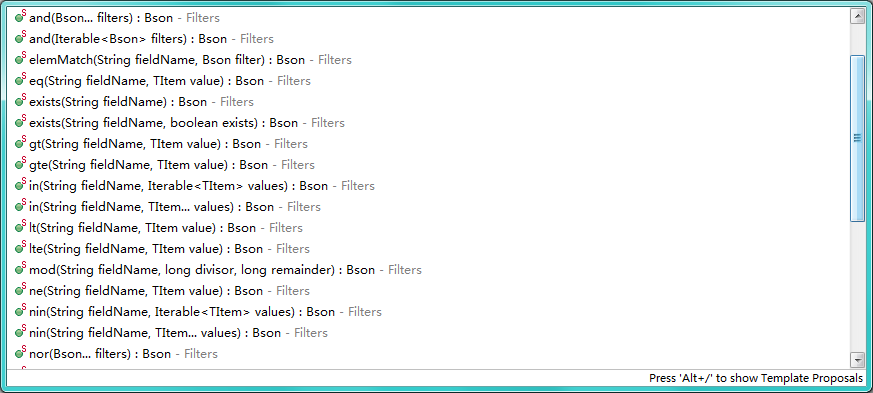至于都是什么意思我就不多解释了。还有排序用的Sorts: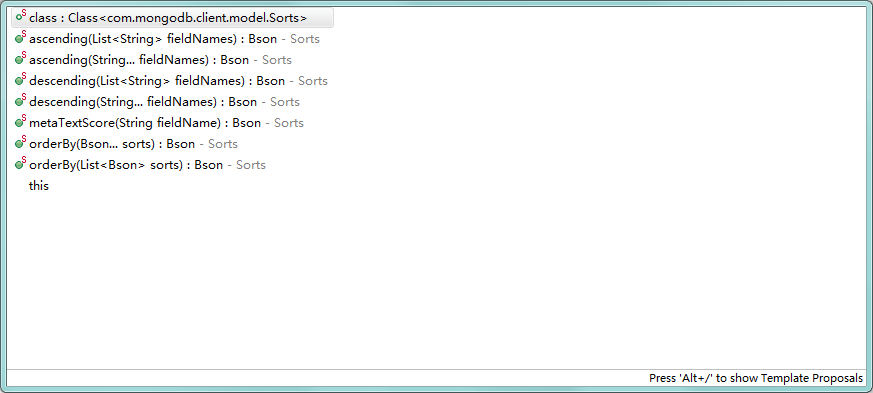
Java MongoDB Bson Filters Sorts -
JSON重复key值
JSON如果一个对象包含了两个`key`值一样,那么会发生什么呢?例如:```json{"name":"喻胜","name":"逗比"}```这个解析的结果获取到的`name`值为`逗比`。
JSON