HTTP断点下载
0
最近看了有些素材网站,很多都有断点下载的功能,自己也写了,但是发现火狐浏览器可以,但是Chrome浏览器却不行。
主要的一些请求头信息如下:
第一次下载:
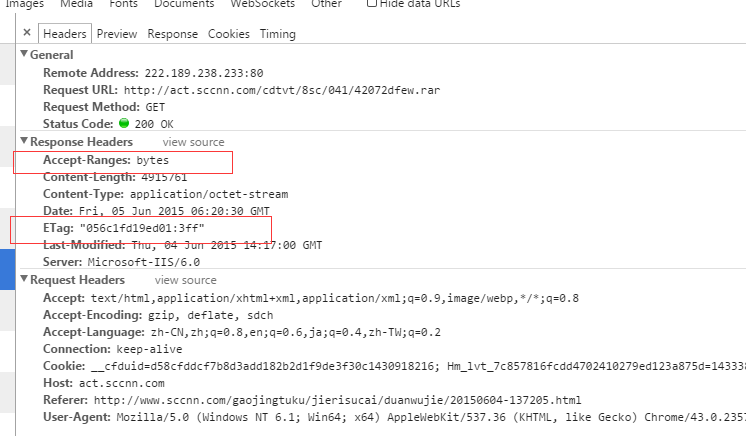
第二次下载:
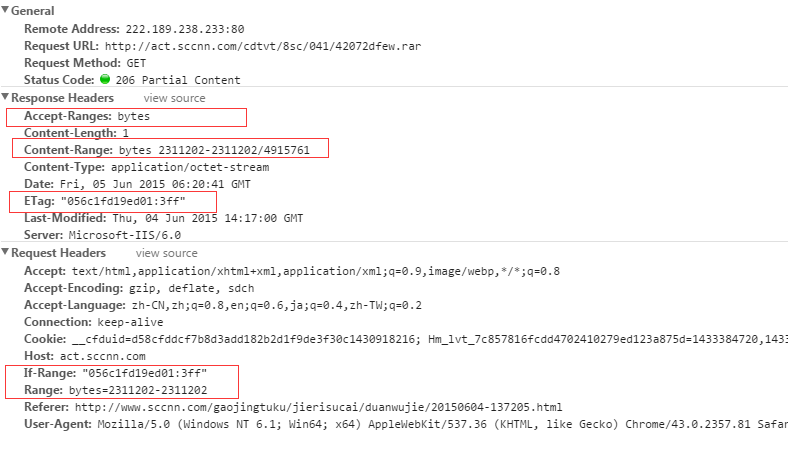
大概代码如下:
String ifRange = request.getHeader("If-Range");
String range = request.getHeader("Range");
if(file == null || !file.exists() || !file.isFile())
return;
long pos = getPos(range);
long available = file.length();
String etag = Integer.toHexString(FilenameUtils.getBaseName(fileName).hashCode()) + ":" + Long.toHexString(available);
response.reset();
response.setBufferSize(0);
response.setHeader("ETag", etag); // 唯一区别当前文件
response.setCharacterEncoding("UTF-8");
response.setHeader("Accept-Ranges", "bytes");
response.setHeader("Content-Type", "application/octet-stream");
response.setHeader("Content-Length", String.valueOf(available));
response.setHeader("Content-Disposition", "attachment; filename=" + fileName);
InputStream is = null;
try {
if(etag.equals(ifRange) && StringUtils.isNotEmpty(range)) {
response.setStatus(HttpServletResponse.SC_PARTIAL_CONTENT); // 续传的时候设置状态码为206
response.setHeader("Content-Range", getContentRange(pos, available));
}
OutputStream os = response.getOutputStream();
is = new FileInputStream(file);
if(etag.equals(ifRange) && StringUtils.isNotEmpty(range))
is.skip(pos); // 跳过已经下载的数据
byte[] bytes = new byte[downSpeed];
int index = 0;
while ((index = is.read(bytes)) != -1) {
os.write(bytes, 0, index);
try {
Thread.sleep(SLEEP_TIME);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
os.flush();
} catch (IOException e) {
logger.error("客户端取消下载,文件大小:" + (available) / 1024 / 1024 + "M,错误信息:" + e.getClass() + ";" + e.getMessage());
} finally {
IOUtils.closeQuietly(is);
}
上面的代码火狐浏览器可以,但是Chrome浏览器每次在设置状态码为206的时候就会重新发起一个新请求,就不能获取到断点信息。
参考文章:http://www.shaojiahao.org/java/java-servlet-http-break-download